 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketchFaceGS: Real-Time Sketch-Driven Face Editing and Generation with Gaussian Splatting
Apr 21, 20263D Gaussian representations have emerged as a powerful paradigm for digital head modeling, achieving photorealistic quality with real-time rendering. However, intuitive and interactive creation or editing of 3D Gaussian head models remains challenging. Although 2D sketches provide an ideal interaction modality for fast, intuitive conceptual design, they are sparse, depth-ambiguous, and lack high-frequency appearance cues, making it difficult to infer dense, geometrically consistent 3D Gaussian structures from strokes - especially under real-time constraints. To address these challenges, we propose SketchFaceGS, the first sketch-driven framework for real-time generation and editing of photorealistic 3D Gaussian head models from 2D sketches. Our method uses a feed-forward, coarse-to-fine architecture. A Transformer-based UV feature-prediction module first reconstructs a coarse but geometrically consistent UV feature map from the input sketch, and then a 3D UV feature enhancement module refines it with high-frequency, photorealistic detail to produce a high-fidelity 3D head. For editing, we introduce a UV Mask Fusion technique combined with a layer-by-layer feature-fusion strategy, enabling precise, real-time, free-viewpoint modifications. Extensive experiments show that SketchFaceGS outperforms existing methods in both generation fidelity and editing flexibility, producing high-quality, editable 3D heads from sketches in a single forward pass.
ClinConsensus: A Consensus-Based Benchmark for Evaluating Chinese Medical LLMs across Difficulty Levels
Mar 03, 2026Large language models (LLMs) are increasingly applied to health management, showing promise across disease prevention, clinical decision-making, and long-term care. However, existing medical benchmarks remain largely static and task-isolated, failing to capture the openness, longitudinal structure, and safety-critical complexity of real-world clinical workflows. We introduce ClinConsensus, a Chinese medical benchmark curated, validated, and quality-controlled by clinical experts. ClinConsensus comprises 2500 open-ended cases spanning the full continuum of care--from prevention and intervention to long-term follow-up--covering 36 medical specialties, 12 common clinical task types, and progressively increasing levels of complexity. To enable reliable evaluation of such complex scenarios, we adopt a rubric-based grading protocol and propose the Clinically Applicable Consistency Score (CACS@k). We further introduce a dual-judge evaluation framework, combining a high-capability LLM-as-judge with a distilled, locally deployable judge model trained via supervised fine-tuning, enabling scalable and reproducible evaluation aligned with physician judgment. Using ClinConsensus, we conduct a comprehensive assessment of several leading LLMs and reveal substantial heterogeneity across task themes, care stages, and medical specialties. While top-performing models achieve comparable overall scores, they differ markedly in reasoning, evidence use, and longitudinal follow-up capabilities, and clinically actionable treatment planning remains a key bottleneck. We release ClinConsensus as an extensible benchmark to support the development and evaluation of medical LLMs that are robust, clinically grounded, and ready for real-world deployment.
EMemBench: Interactive Benchmarking of Episodic Memory for VLM Agents
Jan 23, 2026We introduce EMemBench, a programmatic benchmark for evaluating long-term memory of agents through interactive games. Rather than using a fixed set of questions, EMemBench generates questions from each agent's own trajectory, covering both text and visual game environments. Each template computes verifiable ground truth from underlying game signals, with controlled answerability and balanced coverage over memory skills: single/multi-hop recall, induction, temporal, spatial, logical, and adversarial. We evaluate memory agents with strong LMs/VLMs as backbones, using in-context prompting as baselines. Across 15 text games and multiple visual seeds, results are far from saturated: induction and spatial reasoning are persistent bottlenecks, especially in visual setting. Persistent memory yields clear gains for open backbones on text games, but improvements are less consistent for VLM agents, suggesting that visually grounded episodic memory remains an open challenge. A human study further confirms the difficulty of EMemBench.
PLawBench: A Rubric-Based Benchmark for Evaluating LLMs in Real-World Legal Practice
Jan 23, 2026As large language models (LLMs) are increasingly applied to legal domain-specific tasks, evaluating their ability to perform legal work in real-world settings has become essential. However, existing legal benchmarks rely on simplified and highly standardized tasks, failing to capture the ambiguity, complexity, and reasoning demands of real legal practice. Moreover, prior evaluations often adopt coarse, single-dimensional metrics and do not explicitly assess fine-grained legal reasoning. To address these limitations, we introduce PLawBench, a Practical Law Benchmark designed to evaluate LLMs in realistic legal practice scenarios. Grounded in real-world legal workflows, PLawBench models the core processes of legal practitioners through three task categories: public legal consultation, practical case analysis, and legal document generation. These tasks assess a model's ability to identify legal issues and key facts, perform structured legal reasoning, and generate legally coherent documents. PLawBench comprises 850 questions across 13 practical legal scenarios, with each question accompanied by expert-designed evaluation rubrics, resulting in approximately 12,500 rubric items for fine-grained assessment. Using an LLM-based evaluator aligned with human expert judgments, we evaluate 10 state-of-the-art LLMs. Experimental results show that none achieves strong performance on PLawBench, revealing substantial limitations in the fine-grained legal reasoning capabilities of current LLMs and highlighting important directions for future evaluation and development of legal LLMs. Data is available at: https://github.com/skylenage/PLawbench.
Towards Storage-Efficient Visual Document Retrieval: An Empirical Study on Reducing Patch-Level Embeddings
Jun 05, 2025Despite the strong performance of ColPali/ColQwen2 in Visualized Document Retrieval (VDR), it encodes each page into multiple patch-level embeddings and leads to excessive memory usage. This empirical study investigates methods to reduce patch embeddings per page at minimum performance degradation. We evaluate two token-reduction strategies: token pruning and token merging. Regarding token pruning, we surprisingly observe that a simple random strategy outperforms other sophisticated pruning methods, though still far from satisfactory. Further analysis reveals that pruning is inherently unsuitable for VDR as it requires removing certain page embeddings without query-specific information. Turning to token merging (more suitable for VDR), we search for the optimal combinations of merging strategy across three dimensions and develop Light-ColPali/ColQwen2. It maintains 98.2% of retrieval performance with only 11.8% of original memory usage, and preserves 94.6% effectiveness at 2.8% memory footprint. We expect our empirical findings and resulting Light-ColPali/ColQwen2 offer valuable insights and establish a competitive baseline for future research towards efficient VDR.
MTR-Bench: A Comprehensive Benchmark for Multi-Turn Reasoning Evaluation
May 26, 2025Recent advances in Large Language Models (LLMs) have shown promising results in complex reasoning tasks. However, current evaluations predominantly focus on single-turn reasoning scenarios, leaving interactive tasks largely unexplored. We attribute it to the absence of comprehensive datasets and scalable automatic evaluation protocols. To fill these gaps, we present MTR-Bench for LLMs' Multi-Turn Reasoning evaluation. Comprising 4 classes, 40 tasks, and 3600 instances, MTR-Bench covers diverse reasoning capabilities, fine-grained difficulty granularity, and necessitates multi-turn interactions with the environments. Moreover, MTR-Bench features fully-automated framework spanning both dataset constructions and model evaluations, which enables scalable assessment without human interventions. Extensive experiments reveal that even the cutting-edge reasoning models fall short of multi-turn, interactive reasoning tasks. And the further analysis upon these results brings valuable insights for future research in interactive AI systems.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025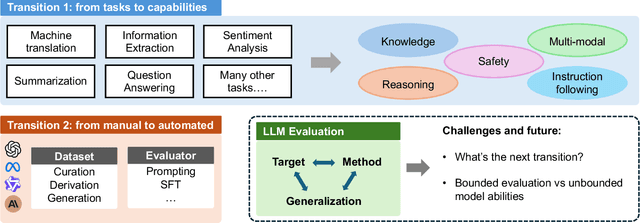
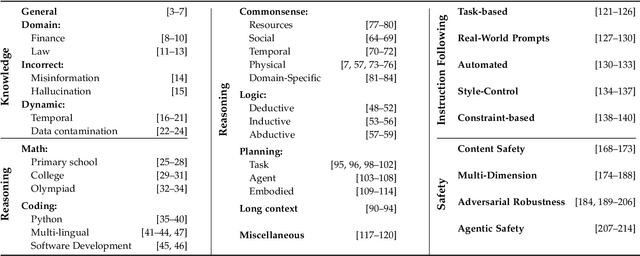
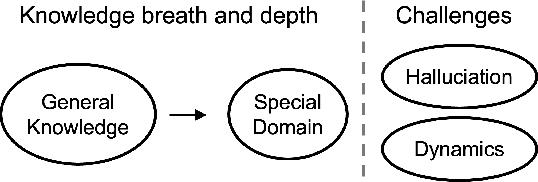
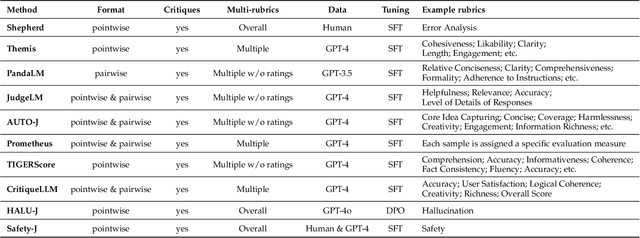
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.
Synergistic Weak-Strong Collaboration by Aligning Preferences
Apr 22, 2025Current Large Language Models (LLMs) excel in general reasoning yet struggle with specialized tasks requiring proprietary or domain-specific knowledge. Fine-tuning large models for every niche application is often infeasible due to black-box constraints and high computational overhead. To address this, we propose a collaborative framework that pairs a specialized weak model with a general strong model. The weak model, tailored to specific domains, produces initial drafts and background information, while the strong model leverages its advanced reasoning to refine these drafts, extending LLMs' capabilities to critical yet specialized tasks. To optimize this collaboration, we introduce a collaborative feedback to fine-tunes the weak model, which quantifies the influence of the weak model's contributions in the collaboration procedure and establishes preference pairs to guide preference tuning of the weak model. We validate our framework through experiments on three domains. We find that the collaboration significantly outperforms each model alone by leveraging complementary strengths. Moreover, aligning the weak model with the collaborative preference further enhances overall performance.
InternLM-XComposer2.5-Reward: A Simple Yet Effective Multi-Modal Reward Model
Jan 21, 2025



Despite the promising performance of Large Vision Language Models (LVLMs) in visual understanding, they occasionally generate incorrect outputs. While reward models (RMs) with reinforcement learning or test-time scaling offer the potential for improving generation quality, a critical gap remains: publicly available multi-modal RMs for LVLMs are scarce, and the implementation details of proprietary models are often unclear. We bridge this gap with InternLM-XComposer2.5-Reward (IXC-2.5-Reward), a simple yet effective multi-modal reward model that aligns LVLMs with human preferences. To ensure the robustness and versatility of IXC-2.5-Reward, we set up a high-quality multi-modal preference corpus spanning text, image, and video inputs across diverse domains, such as instruction following, general understanding, text-rich documents, mathematical reasoning, and video understanding. IXC-2.5-Reward achieves excellent results on the latest multi-modal reward model benchmark and shows competitive performance on text-only reward model benchmarks. We further demonstrate three key applications of IXC-2.5-Reward: (1) Providing a supervisory signal for RL training. We integrate IXC-2.5-Reward with Proximal Policy Optimization (PPO) yields IXC-2.5-Chat, which shows consistent improvements in instruction following and multi-modal open-ended dialogue; (2) Selecting the best response from candidate responses for test-time scaling; and (3) Filtering outlier or noisy samples from existing image and video instruction tuning training data. To ensure reproducibility and facilitate further research, we have open-sourced all model weights and training recipes at https://github.com/InternLM/InternLM-XComposer
Long Context vs. RAG for LLMs: An Evaluation and Revisits
Dec 27, 2024



Extending context windows (i.e., Long Context, LC) and using retrievers to selectively access relevant information (i.e., Retrieval-Augmented Generation, RAG) are the two main strategies to enable LLMs to incorporate extremely long external contexts. This paper revisits recent studies on this topic, highlighting their key insights and discrepancies. We then provide a more comprehensive evaluation by filtering out questions answerable without external context, identifying the most effective retrieval methods, and expanding the datasets. We show that LC generally outperforms RAG in question-answering benchmarks, especially for Wikipedia-based questions. Summarization-based retrieval performs comparably to LC, while chunk-based retrieval lags behind. However, RAG has advantages in dialogue-based and general question queries. These insights underscore the trade-offs between RAG and LC strategies, offering guidance for future optimization of LLMs with external knowledge sources. We also provide an in-depth discussion on this topic, highlighting the overlooked importance of context relevance in existing studies.