 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputer-Aided Design Generation by Cascaded Discrete Diffusion Model
May 06, 2026Recent deep learning approaches seek to automate CAD creation by representing a model as a sequence of discrete commands and parameters, and then generating them using autoregressive models or continuous diffusion operating in Euclidean embedding space. However, continuous diffusion perturbs representations in a continuous Euclidean domain that does not reflect the inherently discrete and heterogeneous nature of CAD tokens, often producing perturbed representations that map to semantically invalid symbols. To overcome this limitation, we propose a cascaded discrete diffusion framework for CAD generation, which consists of a command diffusion for generating CAD commands and a parameter diffusion conditioned on CAD commands. Unlike isotropic Gaussian perturbation, the forward process of our approach operates directly over categorical token distributions using delicate transition matrices. For commands, we adopt an absorbing-state transition matrix that progressively corrupts tokens to a designated symbol; for parameters, we introduce specific transition matrices tailored to heterogeneous attributes: a Gaussian kernel for coordinate continuity, a scale-invariant kernel for dimensional values, and a prior-preserving kernel for boolean attributes. The reverse process is achieved by two denoising networks: a Transformer-based encoder for command recovery, and a parameter network with extra local self-attention for command-level interaction and cross-attention for conditional injection. Experiments on the DeepCAD dataset show that the proposed approach surpasses existing autoregressive and continuous diffusion models on unconditional generation metrics, while qualitative results validate effective controllability in conditional generation tasks. Source codes will be released.
Metric-agnostic Learning-to-Rank via Boosting and Rank Approximation
Apr 16, 2026Learning-to-Rank (LTR) is a supervised machine learning approach that constructs models specifically designed to order a set of items or documents based on their relevance or importance to a given query or context. Despite significant success in real-world information retrieval systems, current LTR methods rely on one prefix ranking metric (e.g., such as Normalized Discounted Cumulative Gain (NDCG) or Mean Average Precision (MAP)) for optimizing the ranking objective function. Such metric-dependent setting limits LTR methods from two perspectives: (1) non-differentiable problem: directly optimizing ranking functions over a given ranking metric is inherently non-smooth, making the training process unstable and inefficient; (2) limited ranking utility: optimizing over one single metric makes it difficult to generalize well to other ranking metrics of interest. To address the above issues, we propose a novel listwise LTR framework for efficient and generalizable ranking purpose. Specifically, we propose a new differentiable ranking loss that combines a smooth approximation to the ranking operator with the average mean square loss per query. Then, we adapt gradient-boosting machines to minimize our proposed loss with respect to each list, a novel contribution. Finally, extensive experimental results confirm that our method outperforms the current state-of-the-art in information retrieval measures with similar efficiency.
Dummy-Aware Weighted Attack (DAWA): Breaking the Safe Sink in Dummy Class Defenses
Mar 31, 2026Adversarial robustness evaluation faces a critical challenge as new defense paradigms emerge that can exploit limitations in existing assessment methods. This paper reveals that Dummy Classes-based defenses, which introduce an additional "dummy" class as a safety sink for adversarial examples, achieve significantly overestimated robustness under conventional evaluation strategies like AutoAttack. The fundamental limitation stems from these attacks' singular focus on misleading the true class label, which aligns perfectly with the defense mechanism--successful attacks are simply captured by the dummy class. To address this gap, we propose Dummy-Aware Weighted Attack (DAWA), a novel evaluation method that simultaneously targets both the true label and dummy label with adaptive weighting during adversarial example synthesis. Extensive experiments demonstrate that DAWA effectively breaks this defense paradigm, reducing the measured robustness of a leading Dummy Classes-based defense from 58.61% to 29.52% on CIFAR-10 under l_infty perturbation (epsilon=8/255). Our work provides a more reliable benchmark for evaluating this emerging class of defenses and highlights the need for continuous evolution of robustness assessment methodologies.
Differentiable Zero-One Loss via Hypersimplex Projections
Feb 26, 2026Recent advances in machine learning have emphasized the integration of structured optimization components into end-to-end differentiable models, enabling richer inductive biases and tighter alignment with task-specific objectives. In this work, we introduce a novel differentiable approximation to the zero-one loss-long considered the gold standard for classification performance, yet incompatible with gradient-based optimization due to its non-differentiability. Our method constructs a smooth, order-preserving projection onto the n,k-dimensional hypersimplex through a constrained optimization framework, leading to a new operator we term Soft-Binary-Argmax. After deriving its mathematical properties, we show how its Jacobian can be efficiently computed and integrated into binary and multiclass learning systems. Empirically, our approach achieves significant improvements in generalization under large-batch training by imposing geometric consistency constraints on the output logits, thereby narrowing the performance gap traditionally observed in large-batch training.
S$^4$C: Speculative Sampling with Syntactic and Semantic Coherence for Efficient Inference of Large Language Models
Jun 17, 2025Large language models (LLMs) exhibit remarkable reasoning capabilities across diverse downstream tasks. However, their autoregressive nature leads to substantial inference latency, posing challenges for real-time applications. Speculative sampling mitigates this issue by introducing a drafting phase followed by a parallel validation phase, enabling faster token generation and verification. Existing approaches, however, overlook the inherent coherence in text generation, limiting their efficiency. To address this gap, we propose a Speculative Sampling with Syntactic and Semantic Coherence (S$^4$C) framework, which extends speculative sampling by leveraging multi-head drafting for rapid token generation and a continuous verification tree for efficient candidate validation and feature reuse. Experimental results demonstrate that S$^4$C surpasses baseline methods across mainstream tasks, offering enhanced efficiency, parallelism, and the ability to generate more valid tokens with fewer computational resources. On Spec-bench benchmarks, S$^4$C achieves an acceleration ratio of 2.26x-2.60x, outperforming state-of-the-art methods.
GCAL: Adapting Graph Models to Evolving Domain Shifts
May 22, 2025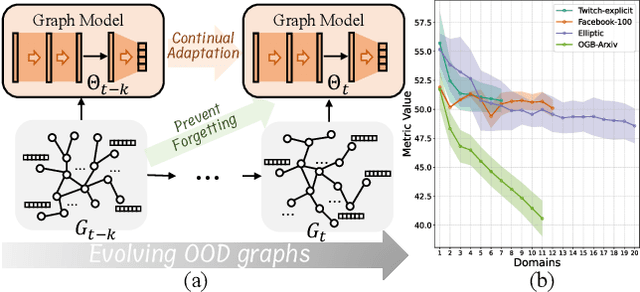
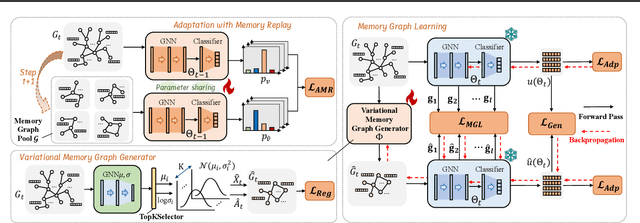
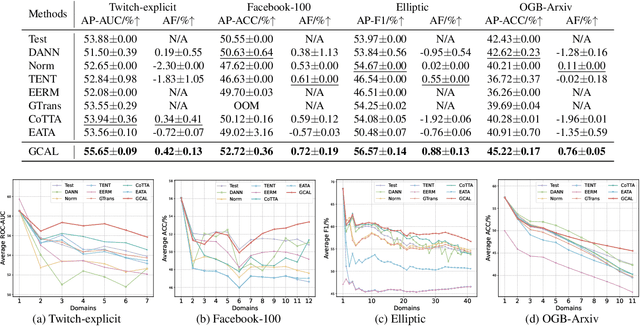
This paper addresses the challenge of graph domain adaptation on evolving, multiple out-of-distribution (OOD) graphs. Conventional graph domain adaptation methods are confined to single-step adaptation, making them ineffective in handling continuous domain shifts and prone to catastrophic forgetting. This paper introduces the Graph Continual Adaptive Learning (GCAL) method, designed to enhance model sustainability and adaptability across various graph domains. GCAL employs a bilevel optimization strategy. The "adapt" phase uses an information maximization approach to fine-tune the model with new graph domains while re-adapting past memories to mitigate forgetting. Concurrently, the "generate memory" phase, guided by a theoretical lower bound derived from information bottleneck theory, involves a variational memory graph generation module to condense original graphs into memories. Extensive experimental evaluations demonstrate that GCAL substantially outperforms existing methods in terms of adaptability and knowledge retention.
Disentangled Multi-span Evolutionary Network against Temporal Knowledge Graph Reasoning
May 20, 2025Temporal Knowledge Graphs (TKGs), as an extension of static Knowledge Graphs (KGs), incorporate the temporal feature to express the transience of knowledge by describing when facts occur. TKG extrapolation aims to infer possible future facts based on known history, which has garnered significant attention in recent years. Some existing methods treat TKG as a sequence of independent subgraphs to model temporal evolution patterns, demonstrating impressive reasoning performance. However, they still have limitations: 1) In modeling subgraph semantic evolution, they usually neglect the internal structural interactions between subgraphs, which are actually crucial for encoding TKGs. 2) They overlook the potential smooth features that do not lead to semantic changes, which should be distinguished from the semantic evolution process. Therefore, we propose a novel Disentangled Multi-span Evolutionary Network (DiMNet) for TKG reasoning. Specifically, we design a multi-span evolution strategy that captures local neighbor features while perceiving historical neighbor semantic information, thus enabling internal interactions between subgraphs during the evolution process. To maximize the capture of semantic change patterns, we design a disentangle component that adaptively separates nodes' active and stable features, used to dynamically control the influence of historical semantics on future evolution. Extensive experiments conducted on four real-world TKG datasets show that DiMNet demonstrates substantial performance in TKG reasoning, and outperforms the state-of-the-art up to 22.7% in MRR.
scSiameseClu: A Siamese Clustering Framework for Interpreting single-cell RNA Sequencing Data
May 19, 2025



Single-cell RNA sequencing (scRNA-seq) reveals cell heterogeneity, with cell clustering playing a key role in identifying cell types and marker genes. Recent advances, especially graph neural networks (GNNs)-based methods, have significantly improved clustering performance. However, the analysis of scRNA-seq data remains challenging due to noise, sparsity, and high dimensionality. Compounding these challenges, GNNs often suffer from over-smoothing, limiting their ability to capture complex biological information. In response, we propose scSiameseClu, a novel Siamese Clustering framework for interpreting single-cell RNA-seq data, comprising of 3 key steps: (1) Dual Augmentation Module, which applies biologically informed perturbations to the gene expression matrix and cell graph relationships to enhance representation robustness; (2) Siamese Fusion Module, which combines cross-correlation refinement and adaptive information fusion to capture complex cellular relationships while mitigating over-smoothing; and (3) Optimal Transport Clustering, which utilizes Sinkhorn distance to efficiently align cluster assignments with predefined proportions while maintaining balance. Comprehensive evaluations on seven real-world datasets demonstrate that~\methodname~outperforms state-of-the-art methods in single-cell clustering, cell type annotation, and cell type classification, providing a powerful tool for scRNA-seq data interpretation.
Rethinking Graph Contrastive Learning through Relative Similarity Preservation
May 08, 2025Graph contrastive learning (GCL) has achieved remarkable success by following the computer vision paradigm of preserving absolute similarity between augmented views. However, this approach faces fundamental challenges in graphs due to their discrete, non-Euclidean nature -- view generation often breaks semantic validity and similarity verification becomes unreliable. Through analyzing 11 real-world graphs, we discover a universal pattern transcending the homophily-heterophily dichotomy: label consistency systematically diminishes as structural distance increases, manifesting as smooth decay in homophily graphs and oscillatory decay in heterophily graphs. We establish theoretical guarantees for this pattern through random walk theory, proving label distribution convergence and characterizing the mechanisms behind different decay behaviors. This discovery reveals that graphs naturally encode relative similarity patterns, where structurally closer nodes exhibit collectively stronger semantic relationships. Leveraging this insight, we propose RELGCL, a novel GCL framework with complementary pairwise and listwise implementations that preserve these inherent patterns through collective similarity objectives. Extensive experiments demonstrate that our method consistently outperforms 20 existing approaches across both homophily and heterophily graphs, validating the effectiveness of leveraging natural relative similarity over artificial absolute similarity.
Deep Cut-informed Graph Embedding and Clustering
Mar 09, 2025Graph clustering aims to divide the graph into different clusters. The recently emerging deep graph clustering approaches are largely built on graph neural networks (GNN). However, GNN is designed for general graph encoding and there is a common issue of representation collapse in existing GNN-based deep graph clustering algorithms. We attribute two main reasons for such issue: (i) the inductive bias of GNN models: GNNs tend to generate similar representations for proximal nodes. Since graphs often contain a non-negligible amount of inter-cluster links, the bias results in error message passing and leads to biased clustering; (ii) the clustering guided loss function: most traditional approaches strive to make all samples closer to pre-learned cluster centers, which cause a degenerate solution assigning all data points to a single label thus make all samples and less discriminative. To address these challenges, we investigate graph clustering from a graph cut perspective and propose an innovative and non-GNN-based Deep Cut-informed Graph embedding and Clustering framework, namely DCGC. This framework includes two modules: (i) cut-informed graph encoding; (ii) self-supervised graph clustering via optimal transport. For the encoding module, we derive a cut-informed graph embedding objective to fuse graph structure and attributes by minimizing their joint normalized cut. For the clustering module, we utilize the optimal transport theory to obtain the clustering assignments, which can balance the guidance of proximity to the pre-learned cluster center. With the above two tailored designs, DCGC is more suitable for the graph clustering task, which can effectively alleviate the problem of representation collapse and achieve better performance. We conduct extensive experiments to demonstrate that our method is simple but effective compared with benchmarks.