 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetonymy in vision models undermines attention-based interpretability
May 07, 2026Part-based reasoning is a classical strategy to make a computer vision model directly focus on the object parts that are relevant to the downstream task. In the context of deep learning, this also serves to improve by-design interpretability, often by using part-centric attention mechanisms on top of a latent image representation provided by a standard, black-box model. This approach is based on a locality assumption: that the latent representation of an object part encodes primarily information about the corresponding image region. In this work, we test this basic assumption, measuring intra-object leakage in vision models using part-based attribute annotations. Through a comprehensive experimental evaluation, we show that modern pretrained vision transformers violate the locality assumption and exhibit a strong intra-object leakage, in which each part encodes information from the whole object, a visual metonymy that compromises the faithfulness of attention-based interpretable-by-design methods for part-based reasoning, ultimately rendering them uninterpretable. In addition, we establish an upper bound using a two-stage approach that prevents leakage by design. We then show that this inherently disentangled feature extraction improves attribute-driven part discovery on a variety of tasks, confirming the practical impact of intra-object leakage. Our results uncover a neglected issue affecting the interpretability of part-based representations, such as those in CBMs relying on part-centric concepts, highlighting that two-stage approaches offer a promising way to mitigate it.
Structural Pruning of Large Vision Language Models: A Comprehensive Study on Pruning Dynamics, Recovery, and Data Efficiency
Apr 27, 2026While Large Vision Language Models (LVLMs) demonstrate impressive capabilities, their substantial computational and memory requirements pose deployment challenges on resource-constrained edge devices. Current parameter reduction techniques primarily involve training LVLMs from small language models, but these methods offer limited flexibility and remain computationally intensive. We study a complementary route: compressing existing LVLMs by applying structured pruning to the language model backbone, followed by lightweight recovery training. Specifically, we investigate two structural pruning paradigms: layerwise and widthwise pruning, and pair them with supervised finetuning and knowledge distillation on logits and hidden states. Additionally, we assess the feasibility of conducting recovery training with only a small fraction of the available data. Our results show that widthwise pruning generally maintains better performance in low-resource scenarios, where computational resources are limited or there is insufficient finetuning data. As for the recovery training, finetuning only the multimodal projector is sufficient at small compression levels. Furthermore, a combination of supervised finetuning and hidden-state distillation yields optimal recovery across various pruning levels. Notably, effective recovery can be achieved using just 5% of the original data, while retaining over 95% of the original performance. Through empirical study on three representative LVLM families ranging from 3B to 7B parameters, this study offers actionable insights for practitioners to compress LVLMs without extensive computation resources or sufficient data. The code base is available at https://github.com/YiranHuangIrene/VLMCompression.git.
From Weights to Concepts: Data-Free Interpretability of CLIP via Singular Vector Decomposition
Mar 25, 2026As vision-language models are deployed at scale, understanding their internal mechanisms becomes increasingly critical. Existing interpretability methods predominantly rely on activations, making them dataset-dependent, vulnerable to data bias, and often restricted to coarse head-level explanations. We introduce SITH (Semantic Inspection of Transformer Heads), a fully data-free, training-free framework that directly analyzes CLIP's vision transformer in weight space. For each attention head, we decompose its value-output matrix into singular vectors and interpret each one via COMP (Coherent Orthogonal Matching Pursuit), a new algorithm that explains them as sparse, semantically coherent combinations of human-interpretable concepts. We show that SITH yields coherent, faithful intra-head explanations, validated through reconstruction fidelity and interpretability experiments. This allows us to use SITH for precise, interpretable weight-space model edits that amplify or suppress specific concepts, improving downstream performance without retraining. Furthermore, we use SITH to study model adaptation, showing how fine-tuning primarily reweights a stable semantic basis rather than learning entirely new features.
ProactiveBench: Benchmarking Proactiveness in Multimodal Large Language Models
Mar 19, 2026Effective collaboration begins with knowing when to ask for help. For example, when trying to identify an occluded object, a human would ask someone to remove the obstruction. Can MLLMs exhibit a similar "proactive" behavior by requesting simple user interventions? To investigate this, we introduce ProactiveBench, a benchmark built from seven repurposed datasets that tests proactiveness across different tasks such as recognizing occluded objects, enhancing image quality, and interpreting coarse sketches. We evaluate 22 MLLMs on ProactiveBench, showing that (i) they generally lack proactiveness; (ii) proactiveness does not correlate with model capacity; (iii) "hinting" at proactiveness yields only marginal gains. Surprisingly, we found that conversation histories and in-context learning introduce negative biases, hindering performance. Finally, we explore a simple fine-tuning strategy based on reinforcement learning: its results suggest that proactiveness can be learned, even generalizing to unseen scenarios. We publicly release ProactiveBench as a first step toward building proactive multimodal models.
SEM: Sparse Embedding Modulation for Post-Hoc Debiasing of Vision-Language Models
Mar 19, 2026Models that bridge vision and language, such as CLIP, are key components of multimodal AI, yet their large-scale, uncurated training data introduce severe social and spurious biases. Existing post-hoc debiasing methods often operate directly in the dense CLIP embedding space, where bias and task-relevant information are highly entangled. This entanglement limits their ability to remove bias without degrading semantic fidelity. In this work, we propose Sparse Embedding Modulation (SEM), a post-hoc, zero-shot debiasing framework that operates in a Sparse Autoencoder (SAE) latent space. By decomposing CLIP text embeddings into disentangled features, SEM identifies and modulates bias-relevant neurons while preserving query-relevant ones. This enables more precise, non-linear interventions. Across four benchmark datasets and two CLIP backbones, SEM achieves substantial fairness gains in retrieval and zero-shot classification. Our results demonstrate that sparse latent representations provide an effective foundation for post-hoc debiasing of vision-language models.
Large Multimodal Models as General In-Context Classifiers
Feb 26, 2026Which multimodal model should we use for classification? Previous studies suggest that the answer lies in CLIP-like contrastive Vision-Language Models (VLMs), due to their remarkable performance in zero-shot classification. In contrast, Large Multimodal Models (LMM) are more suitable for complex tasks. In this work, we argue that this answer overlooks an important capability of LMMs: in-context learning. We benchmark state-of-the-art LMMs on diverse datasets for closed-world classification and find that, although their zero-shot performance is lower than CLIP's, LMMs with a few in-context examples can match or even surpass contrastive VLMs with cache-based adapters, their "in-context" equivalent. We extend this analysis to the open-world setting, where the generative nature of LMMs makes them more suitable for the task. In this challenging scenario, LMMs struggle whenever provided with imperfect context information. To address this issue, we propose CIRCLE, a simple training-free method that assigns pseudo-labels to in-context examples, iteratively refining them with the available context itself. Through extensive experiments, we show that CIRCLE establishes a robust baseline for open-world classification, surpassing VLM counterparts and highlighting the potential of LMMs to serve as unified classifiers, and a flexible alternative to specialized models.
Linear Model Merging Unlocks Simple and Scalable Multimodal Data Mixture Optimization
Feb 04, 2026Selecting the best data mixture is critical for successful Supervised Fine-Tuning (SFT) of Multimodal Large Language Models. However, determining the optimal mixture weights across multiple domain-specific datasets remains a significant bottleneck due to the combinatorial search space and the high cost associated with even a single training run. This is the so-called Data Mixture Optimization (DMO) problem. On the other hand, model merging unifies domain-specific experts through parameter interpolation. This strategy is efficient, as it only requires a single training run per domain, yet oftentimes leads to suboptimal models. In this work, we take the best of both worlds, studying model merging as an efficient strategy for estimating the performance of different data mixtures. We train domain-specific multimodal experts and evaluate their weighted parameter-space combinations to estimate the efficacy of corresponding data mixtures. We conduct extensive experiments on 14 multimodal benchmarks, and empirically demonstrate that the merged proxy models exhibit a high rank correlation with models trained on actual data mixtures. This decouples the search for optimal mixtures from the resource-intensive training process, thereby providing a scalable and efficient strategy for navigating the complex landscape of mixture weights. Code is publicly available at https://github.com/BerasiDavide/mLLMs_merging_4_DMO.
Investigating Structural Pruning and Recovery Techniques for Compressing Multimodal Large Language Models: An Empirical Study
Jul 28, 2025
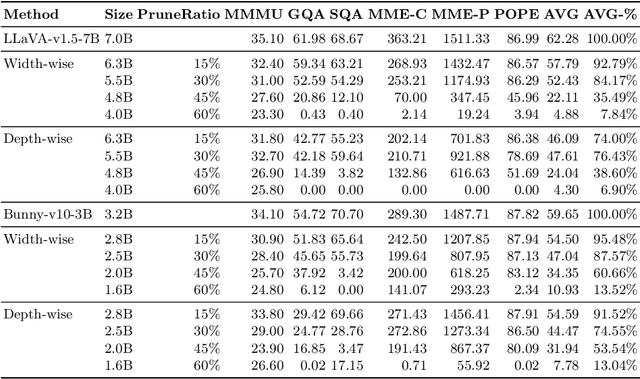
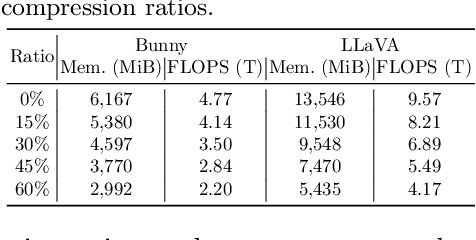

While Multimodal Large Language Models (MLLMs) demonstrate impressive capabilities, their substantial computational and memory requirements pose significant barriers to practical deployment. Current parameter reduction techniques primarily involve training MLLMs from Small Language Models (SLMs), but these methods offer limited flexibility and remain computationally intensive. To address this gap, we propose to directly compress existing MLLMs through structural pruning combined with efficient recovery training. Specifically, we investigate two structural pruning paradigms--layerwise and widthwise pruning--applied to the language model backbone of MLLMs, alongside supervised finetuning and knowledge distillation. Additionally, we assess the feasibility of conducting recovery training with only a small fraction of the available data. Our results show that widthwise pruning generally maintains better performance in low-resource scenarios with limited computational resources or insufficient finetuning data. As for the recovery training, finetuning only the multimodal projector is sufficient at small compression levels (< 20%). Furthermore, a combination of supervised finetuning and hidden-state distillation yields optimal recovery across various pruning levels. Notably, effective recovery can be achieved with as little as 5% of the original training data, while retaining over 95% of the original performance. Through empirical study on two representative MLLMs, i.e., LLaVA-v1.5-7B and Bunny-v1.0-3B, this study offers actionable insights for practitioners aiming to compress MLLMs effectively without extensive computation resources or sufficient data.
Classifier-to-Bias: Toward Unsupervised Automatic Bias Detection for Visual Classifiers
Apr 29, 2025A person downloading a pre-trained model from the web should be aware of its biases. Existing approaches for bias identification rely on datasets containing labels for the task of interest, something that a non-expert may not have access to, or may not have the necessary resources to collect: this greatly limits the number of tasks where model biases can be identified. In this work, we present Classifier-to-Bias (C2B), the first bias discovery framework that works without access to any labeled data: it only relies on a textual description of the classification task to identify biases in the target classification model. This description is fed to a large language model to generate bias proposals and corresponding captions depicting biases together with task-specific target labels. A retrieval model collects images for those captions, which are then used to assess the accuracy of the model w.r.t. the given biases. C2B is training-free, does not require any annotations, has no constraints on the list of biases, and can be applied to any pre-trained model on any classification task. Experiments on two publicly available datasets show that C2B discovers biases beyond those of the original datasets and outperforms a recent state-of-the-art bias detection baseline that relies on task-specific annotations, being a promising first step toward addressing task-agnostic unsupervised bias detection.
On Large Multimodal Models as Open-World Image Classifiers
Mar 27, 2025



Traditional image classification requires a predefined list of semantic categories. In contrast, Large Multimodal Models (LMMs) can sidestep this requirement by classifying images directly using natural language (e.g., answering the prompt "What is the main object in the image?"). Despite this remarkable capability, most existing studies on LMM classification performance are surprisingly limited in scope, often assuming a closed-world setting with a predefined set of categories. In this work, we address this gap by thoroughly evaluating LMM classification performance in a truly open-world setting. We first formalize the task and introduce an evaluation protocol, defining various metrics to assess the alignment between predicted and ground truth classes. We then evaluate 13 models across 10 benchmarks, encompassing prototypical, non-prototypical, fine-grained, and very fine-grained classes, demonstrating the challenges LMMs face in this task. Further analyses based on the proposed metrics reveal the types of errors LMMs make, highlighting challenges related to granularity and fine-grained capabilities, showing how tailored prompting and reasoning can alleviate them.