 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Scalable Terminal Task Synthesis via Skill Graphs
Apr 28, 2026Terminal agents have demonstrated strong potential for autonomous command-line execution, yet their training remains constrained by the scarcity of high-quality and diverse execution trajectories. Existing approaches mitigate this bottleneck by synthesizing large-scale terminal task instances for trajectory sampling. However, they primarily focus on scaling the number of tasks while providing limited control over the diversity of execution trajectories that agents actually experience during training. In this paper, we present SkillSynth, an automated framework for terminal task synthesis built on a scenario-mediated skill graph. SkillSynth first constructs a large-scale skill graph, where scenarios serve as intermediate transition nodes that connect diverse command-line skills. It then samples paths from this graph as abstractions of real-world workflows, and uses a multi-agent harness to instantiate them into executable task instances. By grounding task synthesis in graph-sampled workflow paths, SkillSynth explicitly controls the diversity of minimal execution trajectories required to solve the synthesized tasks. Experiments on Terminal-Bench demonstrate the effectiveness of SkillSynth. Moreover, task instances synthesized by SkillSynth have been adopted to train Hy3 Preview, contributing to its enhanced agentic capabilities in terminal-based settings.
WRAP++: Web discoveRy Amplified Pretraining
Apr 09, 2026Synthetic data rephrasing has emerged as a powerful technique for enhancing knowledge acquisition during large language model (LLM) pretraining. However, existing approaches operate at the single-document level, rewriting individual web pages in isolation. This confines synthesized examples to intra-document knowledge, missing cross-document relationships and leaving facts with limited associative context. We propose WRAP++ (Web discoveRy Amplified Pretraining), which amplifies the associative context of factual knowledge by discovering cross-document relationships from web hyperlinks and synthesizing joint QA over each discovered document pair. Concretely, WRAP++ discovers high-confidence relational motifs including dual-links and co-mentions, and synthesizes QA that requires reasoning across both documents. This produces relational knowledge absent from either source document alone, creating diverse entry points to the same facts. Because the number of valid entity pairs grows combinatorially, this discovery-driven synthesis also amplifies data scale far beyond single-document rewriting. Instantiating WRAP++ on Wikipedia, we amplify ~8.4B tokens of raw text into 80B tokens of cross-document QA data. On SimpleQA, OLMo-based models at both 7B and 32B scales trained with WRAP++ substantially outperform single-document approaches and exhibit sustained scaling gains, underscoring the advantage of cross-document knowledge discovery and amplification.
Backdoor Sentinel: Detecting and Detoxifying Backdoors in Diffusion Models via Temporal Noise Consistency
Feb 02, 2026Diffusion models have been widely deployed in AIGC services; however, their reliance on opaque training data and procedures exposes a broad attack surface for backdoor injection. In practical auditing scenarios, due to the protection of intellectual property and commercial confidentiality, auditors are typically unable to access model parameters, rendering existing white-box or query-intensive detection methods impractical. More importantly, even after the backdoor is detected, existing detoxification approaches are often trapped in a dilemma between detoxification effectiveness and generation quality. In this work, we identify a previously unreported phenomenon called temporal noise unconsistency, where the noise predictions between adjacent diffusion timesteps is disrupted in specific temporal segments when the input is triggered, while remaining stable under clean inputs. Leveraging this finding, we propose Temporal Noise Consistency Defense (TNC-Defense), a unified framework for backdoor detection and detoxification. The framework first uses the adjacent timestep noise consistency to design a gray-box detection module, for identifying and locating anomalous diffusion timesteps. Furthermore, the framework uses the identified anomalous timesteps to construct a trigger-agnostic, timestep-aware detoxification module, which directly corrects the backdoor generation path. This effectively suppresses backdoor behavior while significantly reducing detoxification costs. We evaluate the proposed method under five representative backdoor attack scenarios and compare it with state-of-the-art defenses. The results show that TNC-Defense improves the average detection accuracy by $11\%$ with negligible additional overhead, and invalidates an average of $98.5\%$ of triggered samples with only a mild degradation in generation quality.
Near-Light Color Photometric Stereo for mono-Chromaticity non-lambertian surface
Jan 19, 2026Color photometric stereo enables single-shot surface reconstruction, extending conventional photometric stereo that requires multiple images of a static scene under varying illumination to dynamic scenarios. However, most existing approaches assume ideal distant lighting and Lambertian reflectance, leaving more practical near-light conditions and non-Lambertian surfaces underexplored. To overcome this limitation, we propose a framework that leverages neural implicit representations for depth and BRDF modeling under the assumption of mono-chromaticity (uniform chromaticity and homogeneous material), which alleviates the inherent ill-posedness of color photometric stereo and allows for detailed surface recovery from just one image. Furthermore, we design a compact optical tactile sensor to validate our approach. Experiments on both synthetic and real-world datasets demonstrate that our method achieves accurate and robust surface reconstruction.
Integrating Boundary Assembling into a DNN Framework for Named Entity Recognition in Chinese Social Media Text
Feb 27, 2020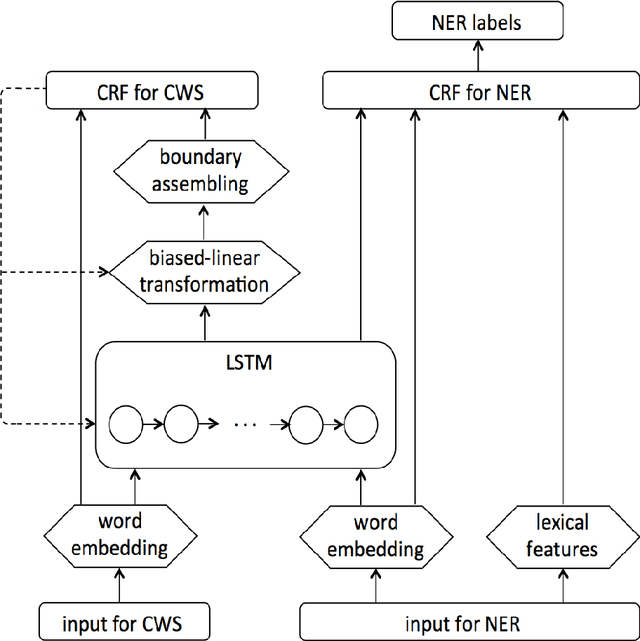
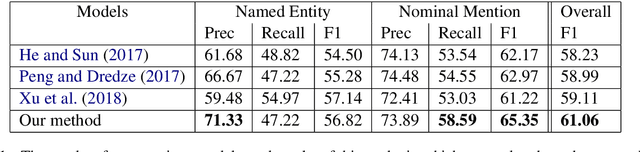
Named entity recognition is a challenging task in Natural Language Processing, especially for informal and noisy social media text. Chinese word boundaries are also entity boundaries, therefore, named entity recognition for Chinese text can benefit from word boundary detection, outputted by Chinese word segmentation. Yet Chinese word segmentation poses its own difficulty because it is influenced by several factors, e.g., segmentation criteria, employed algorithm, etc. Dealt improperly, it may generate a cascading failure to the quality of named entity recognition followed. In this paper we integrate a boundary assembling method with the state-of-the-art deep neural network model, and incorporate the updated word boundary information into a conditional random field model for named entity recognition. Our method shows a 2% absolute improvement over previous state-of-the-art results.