 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnposed-to-3D: Learning Simulation-Ready Vehicles from Real-World Images
Apr 21, 2026Creating realistic and simulation-ready 3D assets is crucial for autonomous driving research and virtual environment construction. However, existing 3D vehicle generation methods are often trained on synthetic data with significant domain gaps from real-world distributions. The generated models often exhibit arbitrary poses and undefined scales, resulting in poor visual consistency when integrated into driving scenes. In this paper, we present Unposed-to-3D, a novel framework that learns to reconstruct 3D vehicles from real-world driving images using image-only supervision. Our approach consists of two stages. In the first stage, we train an image-to-3D reconstruction network using posed images with known camera parameters. In the second stage, we remove camera supervision and use a camera prediction head that directly estimates the camera parameters from unposed images. The predicted pose is then used for differentiable rendering to provide self-supervised photometric feedback, enabling the model to learn 3D geometry purely from unposed images. To ensure simulation readiness, we further introduce a scale-aware module to predict real-world size information, and a harmonization module that adapts the generated vehicles to the target driving scene with consistent lighting and appearance. Extensive experiments demonstrate that Unposed-to-3D effectively reconstructs realistic, pose-consistent, and harmonized 3D vehicle models from real-world images, providing a scalable path toward creating high-quality assets for driving scene simulation and digital twin environments.
SoTCKGE:Continual Knowledge Graph Embedding Based on Spatial Offset Transformation
Mar 11, 2025Current Continual Knowledge Graph Embedding (CKGE) methods primarily rely on translation-based embedding methods, leveraging previously acquired knowledge to initialize new facts. To enhance learning efficiency, these methods often integrate fine-tuning or continual learning strategies. However, this compromises the model's prediction accuracy and the translation-based methods lack support for complex relational structures (multi-hop relations). To tackle this challenge, we propose a novel CKGE framework SoTCKGE grounded in Spatial Offset Transformation. Within this framework, entity positions are defined as being jointly determined by base position vectors and offset vectors. This not only enhances the model's ability to represent complex relational structures but also allows for the embedding update of both new and old knowledge through simple spatial offset transformations, without the need for continuous learning methods. Furthermore, we introduce a hierarchical update strategy and a balanced embedding method to refine the parameter update process, effectively minimizing training costs and augmenting model accuracy. To comprehensively assess the performance of our model, we have conducted extensive experimlents on four publicly accessible datasets and a new dataset constructed by us. Experimental results demonstrate the advantage of our model in enhancing multi-hop relationship learning and further improving prediction accuracy.
Towards Realistic Visual Dubbing with Heterogeneous Sources
Jan 17, 2022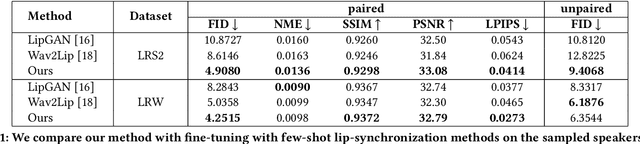
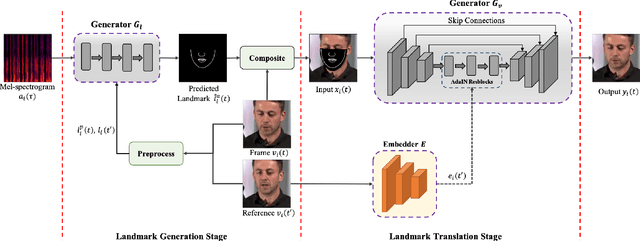
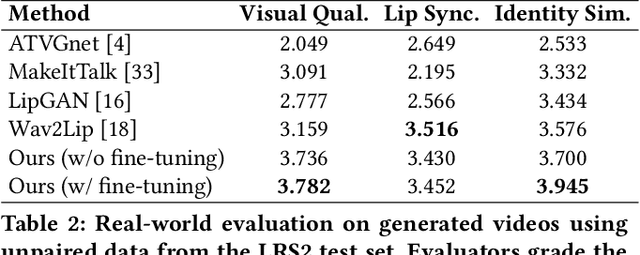
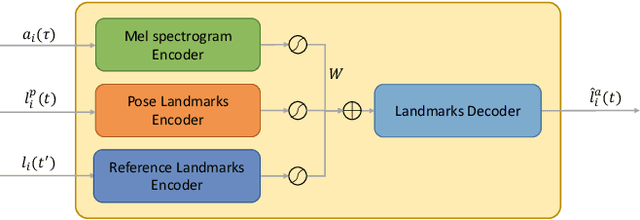
The task of few-shot visual dubbing focuses on synchronizing the lip movements with arbitrary speech input for any talking head video. Albeit moderate improvements in current approaches, they commonly require high-quality homologous data sources of videos and audios, thus causing the failure to leverage heterogeneous data sufficiently. In practice, it may be intractable to collect the perfect homologous data in some cases, for example, audio-corrupted or picture-blurry videos. To explore this kind of data and support high-fidelity few-shot visual dubbing, in this paper, we novelly propose a simple yet efficient two-stage framework with a higher flexibility of mining heterogeneous data. Specifically, our two-stage paradigm employs facial landmarks as intermediate prior of latent representations and disentangles the lip movements prediction from the core task of realistic talking head generation. By this means, our method makes it possible to independently utilize the training corpus for two-stage sub-networks using more available heterogeneous data easily acquired. Besides, thanks to the disentanglement, our framework allows a further fine-tuning for a given talking head, thereby leading to better speaker-identity preserving in the final synthesized results. Moreover, the proposed method can also transfer appearance features from others to the target speaker. Extensive experimental results demonstrate the superiority of our proposed method in generating highly realistic videos synchronized with the speech over the state-of-the-art.